
Nagios est un outil de supervision informatique, une référence dans le domaine. De nombreuses sociétés l’utilisent au quotidien pour vérifier l’état de leur infrastructure. Le bon point c’est qu’avec un usage aussi répandu, il y a de nombreuses ressources partagées pour faire ce que l’on veut. Et avec le plugin Checks Nagios, ses possibilités sont disponibles pour Jeedom.
![]()
Nagios : qu’est-ce que c’est ?
Nagios est souvent vu comme un logiciel unique, pourtant aujourd’hui c’est plus un framework et aussi un « standard » sur quelques points (on entend souvent parler de « on peut le monitorer avec Nagios ? »)
![]()
Historiquement c’est un logiciel de supervision sans interface graphique, un moteur qui contient pour faire simple :
- « checks » : ce sont des scripts que Nagios execute pour vérifier un état
- alertes : ce sont des scripts qui vont être éxécuté au besoin
- contacts : les personnes à notifier avec les alertes
- calendriers : pour les contacts
- les équipements à superviser
- une liste d’éléments de supervision qui est une combinaison : équipement / check / fréquence/calendrier
Ainsi le but est de lui dire par exemple :
- toutes les 5mn vérifie que le serveur est joignable
- toutes les 15mn vérifier que les disques sont OK
- …
C’est basique et grossier comme description mais ca vous donne une idée. Alors après sont apparues des interfaces web pour visualiser les résultats ou configuration Nagios (Thruk, Centreon …) Et plusieurs forks depuis la dernière version (Shinken, Icinga …)
Par exemple Shinken a tout réécrit pour pouvoir diviser tous les rôles unitaires de Nagios et les répartir de facon scalable et redondante pour avoir une vraie plateforme HA sans bidouillage ou point central bloquant.
Car oui, les « nagioslike » ont dans leurs palmarès des infrastructures à plusieurs centaines de milliers d’éléments supervisés.
Les checks
Petit focus sur les checks nagios en eux mêmes. Ils sont standardisés dans le sens où :
- ils doivent avoir un code de sortie qui respecte : 0 c’est OK, 1 on est en situation d’un avertissement, 2 c’est un état critique, 3 état inconnue.
- la sortie standard constitue ce qui doit être affiché
- si il y a des métriques, ils sont après un | et chaque métrique est séparé par un espace
Bref, c’est un format codifié et assez simple pour que beaucoup de personnes puissent compléter si besoin
Checks Nagios, le plugin Jeedom : qu’est-ce qu’il fait ?
Alors si c’est pour les infrastructures gigantesques, que vient faire Nagios dans notre domotique ?
Et bien c’est pas Nagios au complet, mais juste les checks. Point d’intégration de nagios ou d’un fork à communiquer avec Jeedom, en fait le serveur Nagios c’est Jeedom.
Car finalement, tracer des graphs ? alerter sur condition ? ordonnancer des scripts toutes les X mn ? Jeedom sait faire.
Donc pas besoin d’un Nagios, on a déjà Jeedom. En revanche les checks Nagios représentent une source énorme de scripts de supervision déjà existant. Donc pourquoi ne pas s’en servir directement ?
Et bien c’est ce que je fait le plugin. Pour chaque équipement vous pouvez ajouter des commandes informartions qui vont éxécuter des checks. A chaque commande on peut choisir la fréquence d’éxécution dans une liste déroulante.
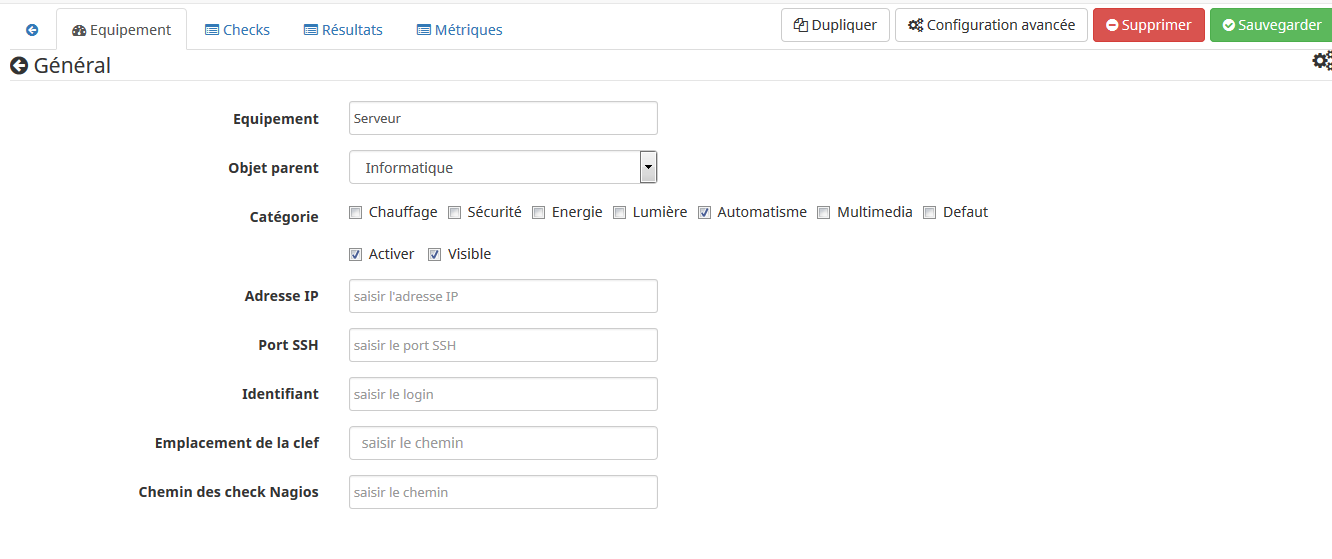
Pour ce qui est du résultat des checks, c’est un état binaire. Sur la page des commandes est affiché en valeur « Statut + Sortie ». A savoir que la commande elle même vaut 1 (binaire OK) si le script c’est bien éxécuté. 0 sinon.
Pour la plupart des usages, cette méthode suffit. Par exemple si on veut vérifier l’état des disques en SMART.
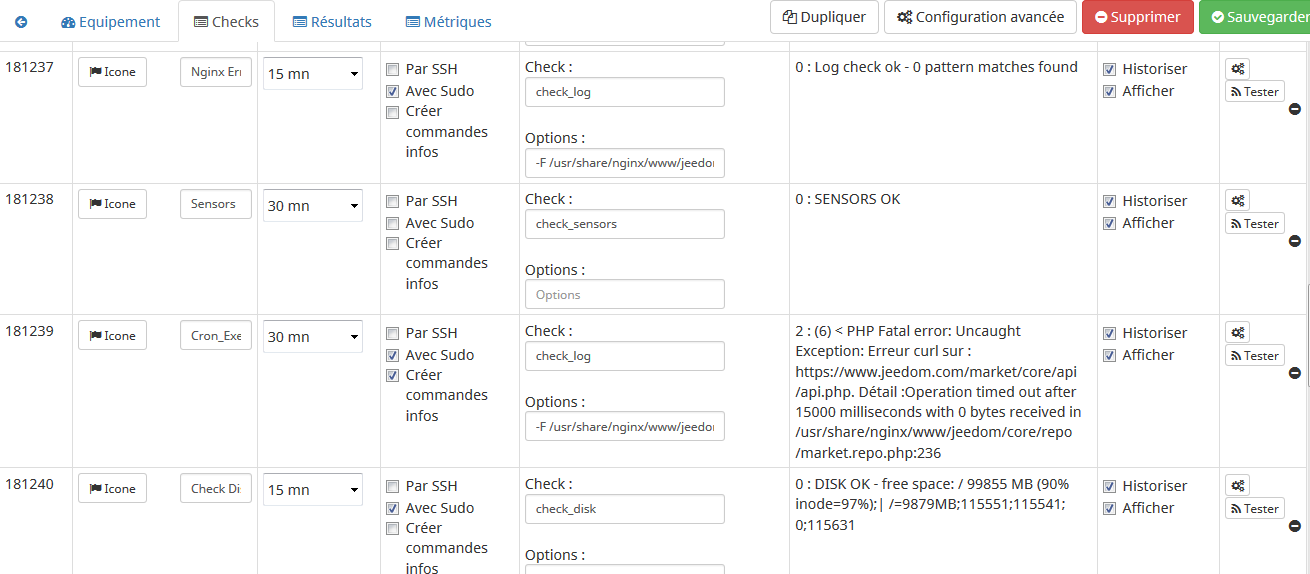
Mais si vous souhaitez utiliser la sortie texte aussi par exemple, il y a une option à cocher qui va créer les commandes complémentaires. Dans ce cas, il y a aura une commande de statut et une commande de sortie créent en plus. Si la commande comporte des métriques, et bien une commande pour chaque métrique en plus.
![]()

On a donc le moyen d’utiliser les check nagios nativement dans Jeedom. De récupérer facilement un état binaire mais aussi les retours évoluer pour tout type d’utilisation immaginable.
Aller plus loin
Notifications
Dans les propriétés avancées de chaque commande désormais (Jeedom 3) il est possible de configurer des notifications sur conditions mais également du déclenchement sur conditions.
Avant le plugin s’en chargeait, maintenant on utilise le core. Mais ca fait pareil en standardisant, quelques exemples :
- sur un check_http en erreur, relancer le service web distant : il suffit de déclarer que si la valeur est égale à 0 alors il faut activer la commande correspondant à une restart nginx par exemple (c’est ce que je fais pour ce blog, superviser depuis Jeedom, avec SSH Commander qui peut relancer Nginx)
- sur un check_RAID défaillant, se notifier par message
- …
Quels checks ?
Par défaut le plugin installe le package monitoring-plugins qui contient pas mal de checks. Quelques checks sont embarqués aussi plus spécifiques à Jeedom. La doc décrit des exemples.
Vous pouvez trouver plus de checks en core sur le site déchange de Nagios.
Mais pas beaucoup de limite, vous pouvez superviser votre Jeedom comme le faisait Jeedom Watcher, vérifier votre RAID, vos process, vos service HTTP (Sickrage, Transmission), votre NAS. Et oui donc c’est pas limité à Jeedom, mais tout ce que vous avez qui peut être vérifier de l’extérieur (service web) ou via une connexion SSH. Ca doit même marche avec un check_nrpe pour monitorer vos Windows.
En l’état, Checks Nagios permet de superviser toute votre infra domotique et pourrait même permettre d’utiliser Jeedom en logiciel de supervision sur de petits besoins du moins.
Produits domotique recommandés sur Bangood
Equipement domotique de qualité à prix compétitif sur Bangood. Voir le catalogue Bangood → (*)
« déchange » => « d’échange »
après je ne regarde plus les fautes 😉
Bonjour,
pour l’utilisation de la sortie texte on doit attendre la prochaine Maj de Jeedom et du plug-in?
En tout cas merci pour le travail et le partage
Oui avec la v3
Salut,
Super ce plugin ! Merci, les possibilités sont illimitées.
Tout fonctionne bien sauf que mes métriques dysfonctionnent à chaque fois que je met à jour le plugin dans Jeedom. Je suis obligé de supprimer et recréer les métriques après chaque MAJ et je perds donc tout mon historique.
Aurais-tu une astuce à me donner ?
Merci encore
J’ai pas ce soucis de mon côté et rien ne l’explique
Voici ce qui se passe suite à une maj, exemple pour le check_ping, id=1744:
Apres la maj, j’ai toujours mon check qui se fait bien avec le bon résultat dans la colonne résultat de l’onglet checks « 0 : PING OK – Packet loss = 0%, RTA = 3.66 ms|rta=3.656000ms;10.000000;30.000000;0.000000 pl=0%;20;50;0 »
Par contre, dans l’onglet résultats, le _outpout ne se met plus a jour : « Résultat de la commande : PING OK – Packet loss = 0%, RTA = 3.78 ms », pourtant l’id source est tjs à 1744…
Et pour finir, dans l’onglet métriques le _rta donne ca : « Résultat de la commande : 1 » , pour lui je vois que le subType est passé en binary au lieu de numeric.
Merci de ton aide et désolé pour gros post
Si besoin, voila les info de la bdd apres la MAJ:
select * FROM cmd where id=1744
id eqLogic_id html eqType logicalId order name configuration template isHistorized type subType unite display isVisible value alert
1744 235 null nagioschecks 1744 0 PING-DNS-Google {« cron »: »5″, »ssh »: »0″, »sudo »: »0″, »cmdoutput »: »1″, »check »: »check_ping », »options »: »-H 8.8.8.8 -w 10,20% -c 30,50% », »code »:0, »status »: »PING OK – Packet loss = 0%, RTA = 3.66 ms|rta=3.656000ms;10.000000;30.000000;0.000000 pl=0%;20;50;0″, »hasMetric »:1, »timeline::enable »: »0″, »historizeMode »: »avg », »historyPurge »: »-1 month »} {« mobile »: »line », »dashboard »: »line »} 1 info binary {« icon »: » »} 1 null null
select * FROM cmd where id=2286
id eqLogic_id html eqType logicalId order name configuration template isHistorized type subType unite display isVisible value alert
2286 235 {« enable »: »0″, »dashboard »: » », »dview »: » », »dplan »: » », »mobile »: » », »mview »: » »} nagioschecks 1744_rta 6 PING-DNS-Google_rta {« type »: »metric », »cmdlink »: »1744″, »minValue »: » », »maxValue »: » », »timeline::enable »: »0″, »calculValueOffset »: » », »historizeRound »: » », »jeedomCheckCmdOperator »: »== », »jeedomCheckCmdTest »: » », »jeedomCheckCmdTime »: » », »historizeMode »: »none », »historyPurge »: »-3 month », »denyValues »: » », »returnStateValue »: » », »returnStateTime »: » », »repeatEventManagement »: »auto », »jeedomPushUrl »: » », »actionCheckCmd »:[], »jeedomPreExecCmd »:[], »jeedomPostExecCmd »:[]} {« mobile »: »line », »dashboard »: »line »} 1 info binary ms {« icon »: » », »generic_type »: » », »showOndashboard »: »1″, »showOnplan »: »1″, »showOnview »: »1″, »showOnmobile »: »1″, »showNameOndashboard »: »1″, »showNameOnplan »: »1″, »showNameOnview »: »1″, »showNameOnmobile »: »1″, »showIconAndNamedashboard »: »0″, »showIconAndNameplan »: »0″, »showIconAndNameview »: »0″, »showIconAndNamemobile »: »0″, »forceReturnLineBefore »: »0″, »forceReturnLineAfter »: »0″, »parameters »:[]} 1 {« warningif »: » », »warningduring »: » », »dangerif »: » », »dangerduring »: » »}
select * FROM cmd where id=2225
id eqLogic_id html eqType logicalId order name configuration template isHistorized type subType unite display isVisible value alert
2225 235 null nagioschecks 1744_output 3 PING-DNS-Google_output {« type »: »output », »cmdlink »: »1744″} {« mobile »: »line », »dashboard »: »line »} 0 info binary {« icon »: » »} 1 null null
Bonjour , j’utilise déjà Nagios au quotidien. Par contre je recherche une interface pour récupérer l’état d’entrée sortie ou contact sec.
Mais je ne trouve pas …